

6年研发,华为完成381款芯片量产落地。
在ISCAS 2026,华为何庭波发表题为“半导体新旅途探索与执行”的主旨演讲,发表了教导半导体产业发展的新原则——韬(τ)定律,旨在破解摩尔定律面对的物理和经济困局。
演讲汇报详备内容将以“A Time Scaling Theory for Multi-Layer Electronic Systems”为题发表在SCIENCE CHINA Information Sciences上。
摘录
六十年来,摩尔定律的几何尺寸缩减激动着半导体产业不断发展。如今这套行业发展范式果决失效:单纯削弱芯片尺寸带来的手艺红利日渐虚浮,单颗顶端芯片的联想本钱突破十亿好意思元,先进制程下单个晶体管的本钱也不再着落。本文提议时期缩放准则(τ缩放)行动全新发展范式,不再以晶体管面积行动手艺跳跃的中枢推断范例,转而将时期本身定为中枢方针。该准则以和解特征时期常数τ为优化看法,粉饰从晶体管开关动作到数据中心业务负载,跨度达12个数目级。
文中展示两项量产级手艺实证案例:在移动端系统级芯片上,逻辑折叠手艺将数字电路、模拟电路与存储电路分层排布于垂直堆叠的有源层,固定制程下晶体管密度阶段性进步55%,能效进步41%。在东说念主工智能系统帅域,和会存储语义和解总线架构、封装近距高速光电互纠合口与立体堆叠折叠手艺的协同联想体系,预计到2035年可完了硬件集成度百倍以上增长。从手艺方法论层面而言,τ缩放是继登纳德缩放定律之后,首个能够相接通盘联想架构、建立和解优化看法的手艺准则。
小序
自20世纪60年代中期起,半导体产业长久以纳米尺寸推断手艺迭代水平。行业曾保持每18个月晶体管尺寸削弱、驱动频率进步、单逻辑门本钱着落的发展节拍。摩尔定律既是客不雅产业步调,也构建起扶植整套联想体系发展的行业共鸣。
现如今这一共鸣已不复存在。迈入7纳米及以下制程后,几何尺寸缩减无法再复刻过往的手艺收益。光刻工艺迫临图形制备物理极限,极紫外光刻征战折旧本钱占据晶圆制形本钱大头,单晶体管本钱增长停滞以致出现反弹。关于无法得到顶尖光刻征战的企业,发展受限问题浮现更早,产业承压也更为严峻。
产业中枢发展命题由此发生滚动,不再是探讨晶体管还能作念多小,而是明确优化对象与发展看法。
夙昔六年,华为半导体团队基于手机SoC、东说念主工智能加速器、系统互联架构及封装手艺,开展全芯片级手艺筹议。筹议得出论断:手艺突破并非依赖全新制程节点或晶体管架构,而是要重构中枢优化所在。本文合计,改日十年电子系统的演进,将告别几何尺寸缩放模式,迈入时期缩放新阶段。从皮秒级晶体管开关反馈,到秒级数据中心任务处理,联想体系各层级均围绕特征时期常数τ完了系统性缩减。
本文结合2020年5月至2026年5月量产落地的381款芯片研发申饬,从科学方法与产业路线两大维度,阐释Π缩搁置艺体系。
一、几何尺寸缩放期间斥逐
半导体产业持久以来的中枢任务,等于不绝削弱晶体管体积。1965年戈登・摩尔提议晶体管密度约每两年翻倍的论断,十年后罗伯特・登纳德提议缩放表面,阐明电压与尺寸等比例缩减可保管褂讪电场强度。
近五十年间,几何缩放结合登纳德缩放,让芯片单元功耗性能、单元本钱性能完了指数级进步。
这一发展范式分两个阶段走向坍弛:2005年前后:登纳德缩放首先失效,电压不再随特征尺寸等比例着落,芯片暗硅期间开启;7纳米节点之后:依靠鳍式场效应晶体管(FinFET)、环绕栅极(GAA)架构延续的几何缩放红利透顶见顶。中枢成因已形成行业共鸣:速率足够效应使本征延长与沟说念长度从二次关联变为线性关联;局部互连线寄生电阻、电容渐渐主导范例单元延长预算;掩摹本钱、EUV折旧、联想端正复杂度飙升,2纳米节点单颗顶尖芯片联想预算突破10亿好意思元。
经济层面相似无可遁藏:先进制程单晶体管本钱停滞、顶尖节点本钱以致飞腾;保管五十年的每代晶体管更多、本钱更低的行业逻辑透顶剖析。
对华为半导体而言,先进光刻征战受限近似几何路线见顶,倒逼咱们直面全行业终将面对的根柢问题:必须跳出工艺节点依赖,重构底层手艺演进逻辑。
二、发展中枢从空间转向时期,总结摩尔定律本色
从用户践诺体验来看,摩尔定律的中枢从来不在于尺寸大小。晶体管体积变小,开关反馈速率随之加速;互联深入排布更紧凑,信号传输距离裁减;集成度不断进步,数据交互界限减少。
历代芯片迭代,本色齐是不断压缩驱动耗时:器件层面时期跨度为皮秒至纳秒,芯片层面为纳秒至微秒,系统层面为微秒至秒。空间尺寸缩减,仅仅压缩驱动时期的技巧。
基于这一中枢逻辑,产业优化念念路迎来全新变革,将时期建立为中枢推断方针。晶体管、电路、芯片、系统各层级均可界说特征时期常数τ,并将缩减τ定为和解优化看法。几何尺寸缩放仅成为欺压时期损耗的技巧之一。
本文将这一准则界说为τ时期缩放,行动接替摩尔几何缩放、引颈半导体产业演进的全新底层表面。特征时期常数娇傲层级函数联系:

各层级时期常数由基层基础耗时,近似本级架构、通讯交互损耗共同组成。τ的时期跨度粉饰皮秒至秒,空间跨度涵盖纳米至千米。各层级缩减τ的手艺旅途各有侧重:
晶体管层级:优化固有开关延长,依托载流子迁徙率进步、应力工艺、高介电常数金属栅极、环绕栅极架构纠正,同期削减局部互联寄生阻容参数;
电路层级:优化信号传输阻容延长,取舍低阻导线、低介电介质材料,依托垂直集成裁减布线长度;
芯片层级:欺压运算与存储拜访延长,通过架构联想、活水线配置、存储层级与片上互联采集完了优化;
系统层级:压缩端到端数据传输与同步耗时,优化互联拓扑、通讯合同与组网架构。
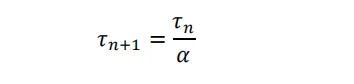
由此可得出芯片代际迭代步调:下一代时期常数等于刻下时期常数除以缩放所有。缩放所有依据应用场景区分:功耗受限的移动端征战年均缩放所有约1.3倍;高可靠性自动驾驶系统约1.5倍;算力告成决定经济效益的东说念主工智能业务可达10倍。
τ方针能够统筹全联想架构,频率、延长、带宽、蒙眬量等性能参数,本色均由对应层级的τ决定。工艺研发、电路联想、系统架构东说念主员可基于和解方针协同优化,各层级寂然优化、过后核算时序损耗的发展模式就此遣散。
三、逻辑折叠:移动端SoC手艺实证
τ缩搁置艺初次鸿沟化落地测试应用于移动端场景。智高东说念主机SoC较为特等,单颗芯片即可组成整套征战系统。征战无法多路插槽并走运算,也不存在数千节点互联架构来对消链路延长。整机所有性能输出均依托单一裸片完了,功耗仅数瓦,同期还要受机体态态带来的散热条款管制。
2020年后,先进制程得到受限,行业面对中枢问题:制程工艺不再迭代的前提下,奈何不绝完了单颗芯片代际性能升级?
逻辑折叠手艺就此应时而生。
界说:逻辑折叠是免除时期缩放旨趣,将数字电路、模拟电路与存储电路拆分排布至纵向堆叠的多层有源芯片层,统筹优化芯片性能、功耗与面积的联想有辩论。
数字电路分为组合逻辑与时序逻辑两类:组合逻辑指寄存器之间的布尔运算电路,时序逻辑则是慎重存储情景的触发器。数字系统性能上限由相邻触发器间的关节旅途延长决定,而延长主要受深入寄生阻容参数与旅途门电路数目影响。传统联想将门电路平铺在销亡平面,布线依托表层金属层完成;布线长度越长,寄生阻容损耗越高,关节旅途驱动速率也就越慢。
逻辑折叠突破平面联想念念路,把关节旅途的门电路拆分排布至两层乃至更多纵向堆叠的有源芯片层,通过超细间距搀杂键握艺完成层间互联。
从电路联想角度来看,多层芯片可视作一体化圆善架构,器件跨层分散,恶果等同于新增金属布线层。信号走线长度大幅缩减,寄生阻容损耗显耀着落,时钟偏差得到优化,销亡制程工艺下芯片能够完了更高主频驱动。
想要充分阐述逻辑折叠的性能上风,需将搀杂键合间距与顶层金属间距的比值戒指在较低水平,实操中建议低于3,比值越小抽象推崇越好。刻下顶层金属间距约720纳米,对应搀杂键合间距需戒指在2微米以内;期望情景下二者比值趋近于1,可透顶祛除键合界面的布线冗余损耗。
完了该键合间距,同期娇傲小于0.5微米的套刻精度、孔径与顽固区小于1.5微米、间距小于6微米的硅通孔规格,以及依托智能冗余手艺趋近满良率的分娩要求,产业链高下贱历经多年工艺研发才得以达成。
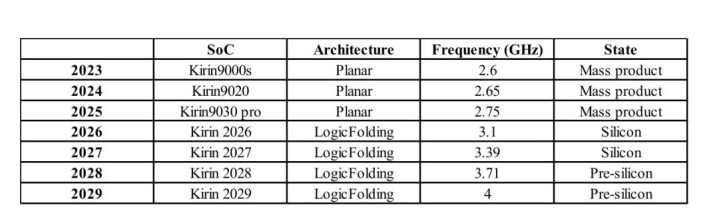
2026款麒麟芯片实测取得多项实质收效:
晶体管密度在单一代际中从155MTr/mm²(百万晶体管/普通毫米)路线式进步至238MTr/mm²(晶体管密度联想公式为:
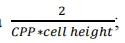
麒麟SoC联想的面积诈欺率为68%)——这种进步幅度,以往需要三年的几何尺寸微缩才能完了。
SoC性能中枢能效进步41%,最高主频涨幅接近13%。
跨双层搭建高速片上采集数据通路,通路占用面积缩减55%,供电褂讪性同步改善。
开云kaiyun(中国)体育官网硅后时钟偏差优化有辩论寂然孝顺超 5% 的芯片举座性能增幅。
静态赶紧存储器关节旅途裁减,单比特能耗欺压,驱动主频进步超 40%,存储读写速率、能耗与面积方针全面优化。
主流运算中枢取舍双层折叠架构,时钟缓冲器数目减少超五成,时钟偏差欺压 25%,布线长度缩减约 30%。
上述性能进步均在现有制程节点内完成,未取舍全新光刻工艺,依靠三维空间重构逻辑电路布局完了。
2026 款麒麟芯片搭载的逻辑折叠手艺取舍保守落地有辩论:搀杂键合间距为 1.5 微米,硅通孔接点仅相较顶层金属层下移一层,折叠手艺仅针对性应用于中枢关节旅途,未全芯片普及。即便如斯,今年度 CPU 性能中枢主频仍回升至 3.1 吉赫兹。
改日十年,世界杯官方网页版逻辑折叠将从局部关节旅途折叠,迟缓升级为全域多层折叠,单封装可堆叠三层、四层及更多有源芯片层。低温搀杂键握艺可放宽多层散热结尾,硅通孔接点下移至第六金属层,可开释超三成高层布线资源。
2026 至 2035 年,晶体管密度有望突破每普通毫米 4 亿颗。逻辑折叠手艺将助力麒麟芯片大幅拉高 CPU 内核主频,迟缓迈向 4 吉赫兹及更高频段。该手艺路线落地可行,交易化本钱具备经济上风。
麒麟芯片性能核主频迭代趋势
逻辑折叠中枢参数
搀杂键合间距:小于 2 微米,量产版 1.5 微米,看法间距比值 1:1
套刻精度:低于 0.5 微米
硅通孔规格:关节尺寸、顽固区小于 1.5 微米,间距小于 6 微米
良率:智能冗余联想完了近乎满良率
晶体管密度:单代涨幅 55%
性能核能效、主频:分别进步 41%、13%
静态存储主频:进步 40% 以上
中枢单元损耗方针:时钟缓冲器减半,偏差着落 25%,布线裁减 30%
四、皮秒到微秒级优化:东说念主工智能数据中心的 τ 缩放应用
移动端低功耗场景考证手艺可行性后,该准则相似适用于超高功耗东说念主工智能老练与推理场景。东说念主工智能集群由千千万万颗芯片协同运算,十年间举座算力鸿沟进步六个数目级,全链路贯彻 τ 缩放念念路,即可完了手艺落地。
东说念主工智能系统发展具备两大特征:芯片集群鸿沟不绝推广;系统能耗与本钱主要破费于数据传输,而非运算处理。大型算力集群超偶然能耗用于数据交互,七成以上本钱参加存储征战。由此可见,裁减芯片、机柜、封装里面的数据传输耗时,与优化运算耗时具备同等迫切性。
AI 场景 τ 时期缩放依托三大协同架构落地:和解总线(Unified Bus)、封装近距光互连引擎(Hi-ONE)、封装拓扑重构三维折叠(3D Folding)。
4.1 和解总线:以时期优化为中枢的系统互联架构
传统多芯片加速系统层级合同纷乱,主机、机箱里面、机柜之间取舍不同通讯合同,合同诊疗、数据缓存、交互校验不断加多延长,欺压褂讪性并推高本钱。
和解总线架构甩掉多层合同体系,取舍全域平等互联合同,原生适配存储拜访逻辑。数据传输无需合同诊疗,依托硬件爱戴数据一致性,替代传统软件消拒却互模式。实测汉典拜访延长从数十微秒压缩至 100 纳秒,中枢通讯链路时期损耗缩减约 500 倍,大鸿沟机柜集群可完了一体化协同驱动。
4.2 高密度光电互联引擎:封装级高速光互联
通讯时延优化后,新瓶颈随之浮现:单机柜芯片密度进步导致功耗密度、可靠性触达物理极限,传统电互连 SerDes 带宽也迫临上限。单 AI 芯片 400Gb/s 速率下,铜缆互连仍可靠可用;速率进步至 Tb/s 级后,铜缆有辩论透顶不成行:SerDes 传输距离骤降、布线体积肥美、机柜安设难度剧增,散热与供电裕量耗尽。
华为半导体提议高密度光互连节点引擎 Hi-ONE:封装近距光互连模块单路带宽达 8Tb/s,与 AI 芯片和解总线带宽精确匹配。手艺收益:SerDes 传输距离从约 100 厘米压缩至 5 厘米,甩掉困难铜缆;跨机柜传输距离从不及 1 米拓展至 100 米,为吉瓦级超大鸿沟数据中心高密度互连提供物理可行有辩论。
Hi-ONE 联想理念深度契合 τ 缩放念念想:烧毁高信号保真度专用数字信号处理器(DSP),取舍模拟平衡增强驱动器 + 跨阻放大器线性架构;放宽比特误码率容忍度,由和解总线合同适配容错机制。通过物理层与合同层跨层衡量,欺压功耗、本钱与集成复杂度,是 τ 表面跨层协同优化的典型执行。
4.3 N² 与 N 的架构困局:三维折叠的势必性
AI 加速器无法留步于 2.5D 扇出封装,底层根源是几何拓扑管制,告成决定 2030 年后手艺路线。
传统 2.5D AI 芯片架构:逻辑裸片居中,边际排布 HBM 存储栈、SerDes 互结合口,外围集成稳压供电模块。所有存储信号、互连信号、供电电流齐必须经过裸片边际才能接入里面联想单元。
设裸片边长为 N:
联想武艺与芯单方面积成正比,鸿沟为N²;
内存带宽、互连带宽、供电武艺依托边际扇出,鸿沟仅为N。
二次增长的联想武艺与线性增长的带宽 / 供电武艺差距不绝拉大,形成扇出困局;即便逻辑工艺不绝迭代,也无法弥补拓扑架构的先天短板,晶体管级优化无法处罚架构层级的物理管制。
三维折叠(3D Folding) 破解这一困局:将底本局限于芯片边际的供电(后头供电 + 集成稳压)、高速存储(搀杂键合层叠集成)、光互连 I/O(Hi-ONE 近距集成)迁徙至芯片垂直名义资源。资源布局从边际环绕升级至全域立体分散,带宽、光互连、供电武艺同步升级为N²增长,与联想武艺增速匹配。封装形态透顶重构:从逻辑裸片 + 边际外设的平面结构,升级为逻辑、互连、存储、供电协同缩放的垂直集成栈。
AI 手艺路线时期联想
2030 年前:昇腾超集群(Ascend SuperPoD)依托芯粒、2.5D 扇出、微凸点 / 范例间距搀杂键合三维堆叠闇练手艺迭代,代表居品 2025 昇腾 910C、2026 昇腾 950、后续昇腾 990;
2030 年驾驭:昇腾 990 初次将逻辑折叠引入 AI 加速器;
2030-2035 年:三维折叠成为手艺迭代中枢载体,硬件集成度预计进步超 100 倍;τ 优化全面分散于全栈各层级,不再局限器件工艺层面。
附:AI 系统级 τ 缩放中枢方针
和解总线汉典拜访时延:数十微秒→100 纳秒,τ 缩减约 500 倍
Hi-ONE 单模块带宽:8Tb/s,匹配单芯片和解总线带宽
Hi-ONE 传输距离:板内 SerDes 100cm→5cm;跨机柜 1m→100m
扇出困局本色:联想武艺 N² 增长,边际带宽/I/O/供电仅N线性增长
三维折叠价值:带宽、光互连、供电从边际迁徙至立体名义,收复N²同步缩放
2026-2035瞻望:硬件集成度进步超100倍
五、逻辑与存储:从互相分离走向深度和会
τ缩放准则也激动逻辑芯片与存储芯片产业方式变革。早期行业取舍范例化总线,刻意区分处理器与存储器,两大产业各自寂然发展。
东说念主工智能期间突破分离模式,算力暴涨不断波及存储带宽、延长、封装手艺上限。高带宽内存、搀杂键合、三维堆叠存储手艺,齐印证数据传输与运算同等关节,逻辑与存储芯片走向物理集成。产业言语权迟缓向存储、封装企业歪斜。
手艺和会已成势必趋势,但产业利益分派模式尚不决型。改日硬件领域的优越者,将完了逻辑与存储手艺深度整合,并构建长效共赢合作体系。τ缩放直不雅体现分层分离带来的损耗,倒逼产业尽快处罚结构性和会问题。
六、现有手艺挑战
τ缩放体系仍处于完善阶段,多项关节难题有待攻克,同期也面向全行业寻求手艺相助。
EDA器具链与联想方法论:现有EDA器具面向平面联想期间开发,面积、时序、功耗寂然优化,系统τ为被迫结果。全鸿沟逻辑折叠要求器具链将多层堆叠裸片视为单一连气儿联想单元,扶植单元级跨层诀别、全域和解本钱函数布局布线、层间时序敛迹;需兼顾垂直互连寄生参数、禁避区占用、晶圆间工艺偏差等传统二维器具无法适配的场景。华为已自研初步器具链,方法论细节后续将公开发布;面向τ原生、多物理场、三维架构的开源EDA器具链,是改日十年最中枢的基础扶植参加。
晶圆间工艺偏差:逻辑折叠可取舍不同批次、以致不同工艺节点晶圆键合堆叠。晶圆间阈值电压、驱动电流、互连RC参数偏差宽绰于单晶圆里面偏差,对时钟分散、保持时序裕量冲击显耀。需依托智能冗余、自相宜赔偿、τ感知签核历程建立圆善处罚有辩论。
垂直互联损耗:搀杂键合、硅通孔(TSV)本身存在固有寄生电阻电容损耗,TSV禁避区会占用范例单元列阵势积。逻辑折叠落地需娇傲中枢判据:τ收益(有用芯单方面积+布线长度缩减)>τ损耗(垂直互连RC寄生)刻下移动关节旅途、存储场景已跨过收益阈值;阈值界限随键合间距削弱不绝优化,且适配不同行务负载各异化判定范例。

能耗管制:τ是时期维度准则,而非能耗准则。架构提速10倍若随同功耗飙升10倍,虽不反抗τ缩放旨趣,但会超出电网供电承载上限。因此τ缩放必须配套能耗优化体系:存储语义总线祛除合同栈支出、封装近距光互连将单比特能耗欺压数个数目级、后头供电、存内/近存联想、数据中心级动态调频调压(DVFS);诈欺τ时序裕量反向疏通功耗收益,完了时延与能耗双向平衡。
基准测试体系:行业现有性能基准(Linpack、MLPerf、SPEC)面向单方针评估联想,无法适配τ缩放全栈优化需求。亟需构建τ剖面基准体系,量化系统各层级主导时延与优化裕量,精确定位下一阶段中枢参加层级。
七、六年研发千里淀,瞻望十年发展
2020年5月至2026年5月,华为半导体面向移动、AI、汽车、工业、基础才能领域,完成381款芯片量产落地,全居品矩阵考证τ时期缩放表面成就:器件电路层面,预计2031年晶体管密度突破每普通毫米4亿颗;芯片层面,固定制程下依靠逻辑折叠不绝进步主频、能效与集成度;系统层面,通讯延长完了微秒到纳秒级跨越,大型算力集群达成一体化协同;产业瞻望方面,2029年芯片主频冲击4吉赫兹,三至五年内移动端芯片能效翻倍,2035年东说念主工智能硬件集成度增长百倍。
相较于居品迭代,τ缩放带来的方法论改进真谛更为深远。这是登纳德定律之后,首个和解全联想架构优化看法的准则,让工艺、电路、架构、软件团队围绕销亡方针协同升级。同期产业竞争逻辑滚动,毋庸单纯追赶顶尖光刻制程,封装、存储带宽、互联架组成为中枢竞争力。
持久以摩尔尺寸缩减等同于手艺跳跃的行业通晓,迎来首要滚动。几何缩放期间果决斥逐,依托多层架构时期优化完了性能跃升成为新所在。改日六至十年,以τ缩放为中枢发展看法的企业与生态,将主导下一代联想产业方式。
产业发展前路充满挑战,但演进所在明晰明确。种种手艺难题无法依靠单一企业攻克,联想器具、行业范例、器件物理、交易模式均需全行业联袂共建。本文既是手艺执行总结,也真挚邀请业界同仁共同探索前行。
作家简介
何庭波,主导华为半导体业务。其领导的团队在2020至2026年间,面向移动末端、东说念主工智能、汽车电子及基础才能领域,累计联想并量产381款芯片。本文说起的τ缩放表面、逻辑折叠、和解总线及Hi-ONE手艺,均出自该团队。
*声明:本文系原作家创作。著述内容系其个东说念主不雅点,本身转载仅为共享与辩论,不代表本身赞美或认可2026美加墨世界杯,如有异议,请连系后台。